Short Description1
How do we turn an ancient text into data? How do we apply data science techniques to historical, cultural, and linguistic questions? What are the ramifications of such transformations when confronted with classical approaches to ancient texts? The Ancient Language Processing course will focus specifically on how to answer the above questions when working with ancient languages and scripts from the emergence of writing in Mesopotamia and Egypt, to the rest of the world up till 800 CE. This course will introduce students of ancient history, ancient Near Eastern languages, and computer science to the computational processing of ancient texts. They will engage with inscribed artefacts–from dataset pre-processing to computational analysis via text parsing, vector space models (VSMs), statistical approaches, and graph theory.
Time: Wednesday 11:00-14:00 IST / 10:00-13:00 CET
Location: Hybrid, on zoom and FU Berlin, room -1.2057
Course Objectives
Ancient languages contain rich human historical and cultural wealth. So far there has been good advancement in applying language technologies to ancient languages such as Sumerian, Akkadian, Latin, Ancient Greek, and Ancient Chinese, especially in the construction of digital language resources and resources to facilitate automatic analysis. For example, the Universal Dependencies (UD) project has made treebanks available for a series of ancient languages. The objective of this course is to computationally engage with ancient datasets of inscribed artefacts, mostly texts, from data exploration to publication of computational analysis. We will analyze classical studies and consider emerging research questions in the field of ancient Near Eastern studies, in order to address them computationally using ancient language processing.
Learning Outcomes
Students will discuss and contrast the shared epigraphical challenges in ancient language processing: such as Latin, non-Latin and non-alphabetic scripts, Right-to-Left, transliteration conventions and fragmentary texts, and in particular, the multilingual framework to represent the morphology, syntax, and semantics, as well as machine translation models. They will perform hands-on digital philology with novel methods, code, and techniques. The main outcome of the course will be a collaborative computational research paper on an ancient dataset.
Instructors
Shai Gordin (Ariel Uni./Open Uni. IL) Email: shaigo@ariel.ac.il |
Eliese-Sophia Lincke (FU Berlin) Email: e.lincke@fu-berlin.de |
Hubert Mara (FU Berlin) Email: hubert.mara@fu-berlin.de |
Footnotes
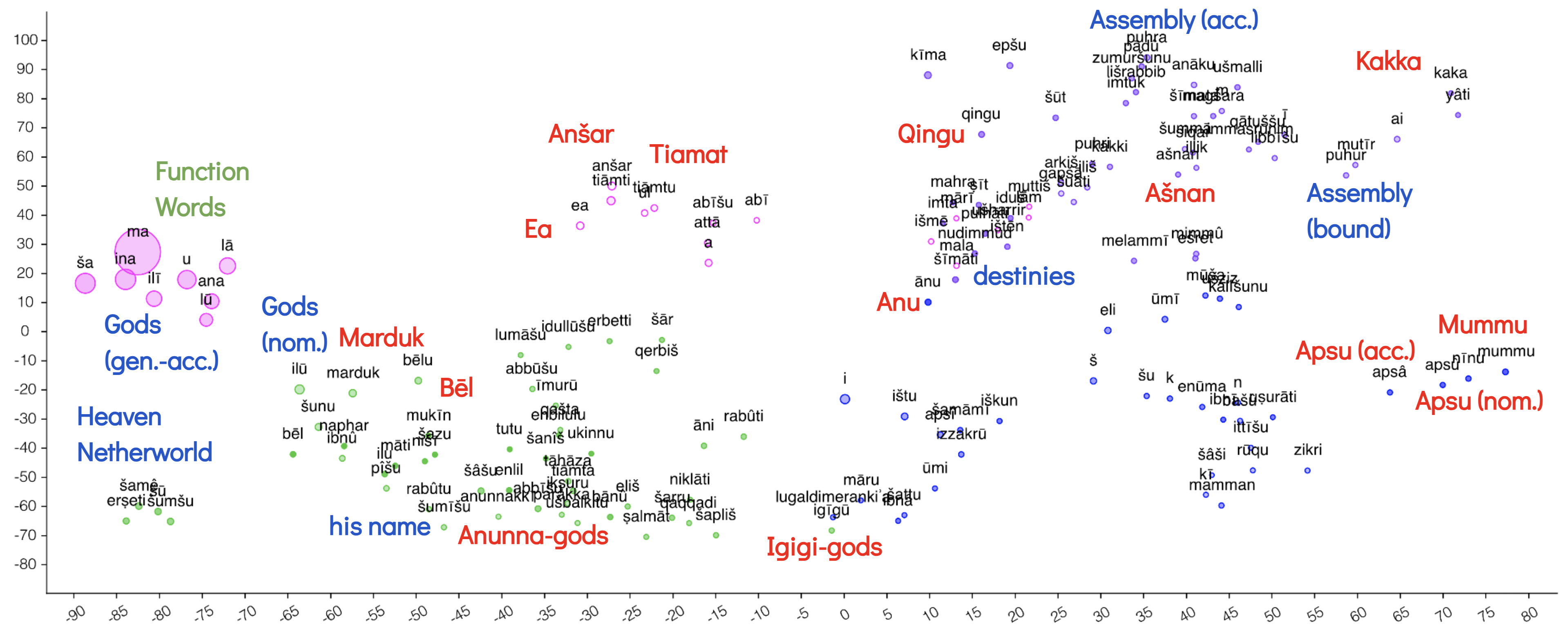
The scatter plot at the top of the page shows relative word frequencies across the seven tablets of Standard Babylonian Enūma eliš (Poem of Creation), using t-SNE dimension reduction to represent relative distances between words in 2D vector space (reproduced using Voyant Tools, see Sinclair, S. & G. Rockwell. (2023). ScatterPlot. Voyant Tools. Retrieved March 21, 2023)↩︎