Word alginment
Contents
Word alginment#
Word alignment refers to the process of establishing correspondences or links between words in parallel texts or bilingual corpora. It is commonly used in natural language processing and machine translation tasks to align words in one language with their corresponding words in another language.
In the context of machine translation, word alignment helps to identify which words in the source language correspond to which words in the target language. This alignment information is valuable for training statistical machine translation models and for understanding the relationships between words in different languages.
Word alignment can be done at different granularities, such as word-to-word alignment or phrase-to-phrase alignment. The alignment process aims to find the most suitable alignment between words in two languages based on their co-occurrence patterns and linguistic similarities.
There are different approaches to word alignment, including statistical methods and rule-based methods. Statistical methods often use alignment models that estimate the probability of a word alignment given a particular translation. These models may consider factors such as word frequencies, sentence lengths, and local context. Rule-based methods, on the other hand, rely on predefined alignment rules or linguistic knowledge to establish word correspondences.
Word alignment is crucial in various applications apart from machine translation. It is used in tasks like bilingual dictionary construction, cross-lingual information retrieval, and corpus analysis. It helps in building resources and models that enable effective language processing and understanding across different languages.
How to align words in different languages#
→ Open the text files with we cerated for the assignment of semantic annotations. → Go to UGARIT and follow there the instruction to cerate an account add there the Akkadian and English text files.
ugarit
Ugarit is a platform a simple and user-friendly environment to facilitate the collection of aligned pairs, which could then be used as training data for the development of automatic translation, alignment models, translations studies, etc
→ Open a new alignment project and put the Akkadina and English texts respectively:
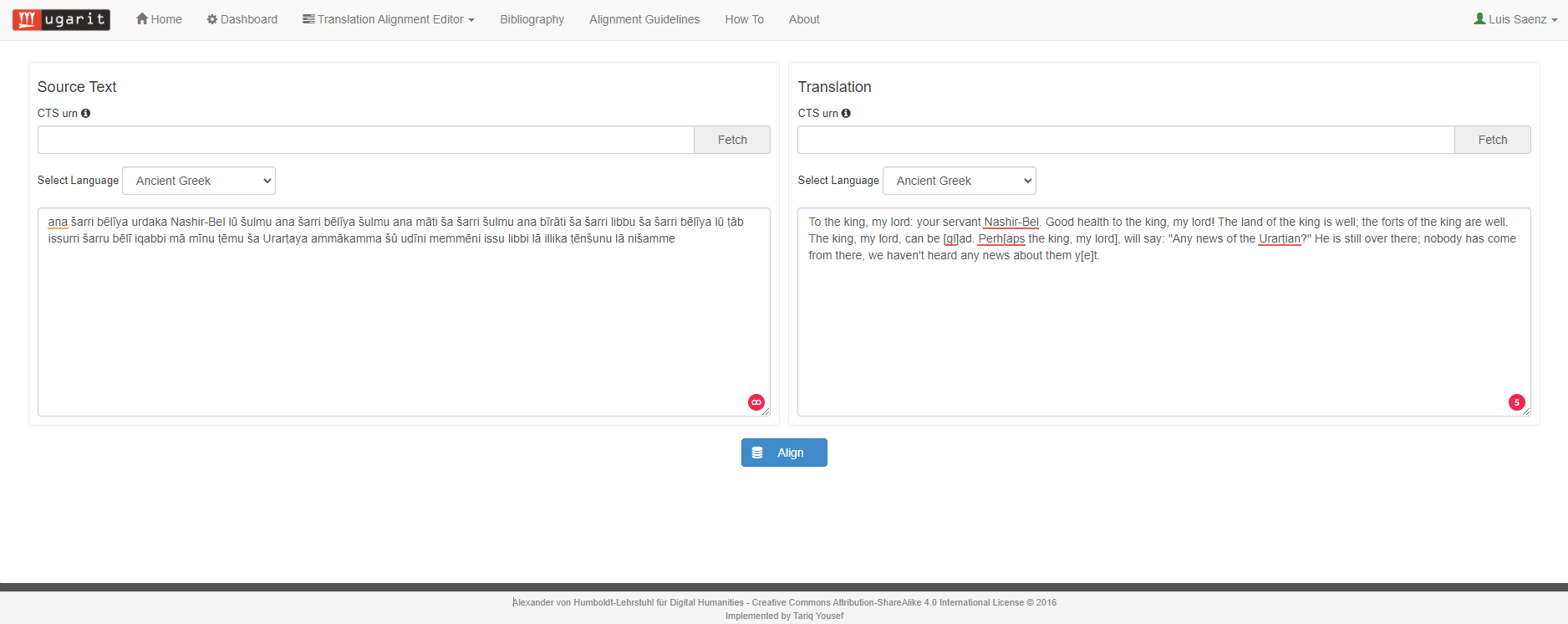
Fig. 7 New Akkadian-English alignment project.#
→ Align the Akkadian-English equivalences. → Save and close
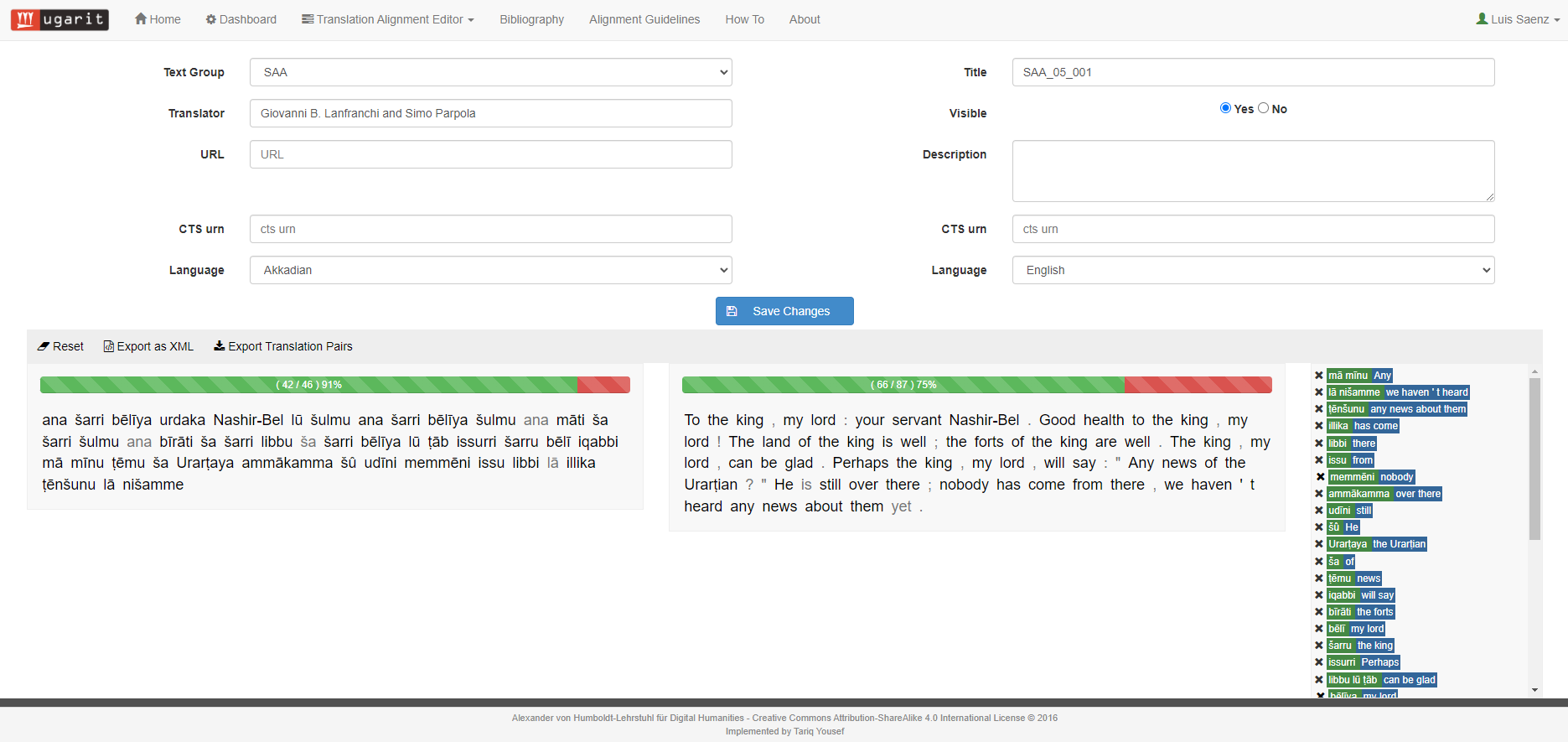
Fig. 8 Aligned Akkadian-English words.#
This method gives the student a closer reading of the akkadian text as he or she has to know what is the equivalent of an Akkadian word in English. The generated data can be used for other NLP tasks.